Premature optimization is the root of all evil (or at least most of it) in programming.
Donald Knuth
Internet n'est pas (que) le « web »
Commençons par un peu d'histoire et de vocabulaire.
La naissance du réseau des réseaux
Les origines d'Internet remontent à la fin des années 1960, lorsque la DARPA (agence gérant les projets de recherche de l'armée américaine) invente Arpanet, un réseau décentralisé reliant à l'origine quelques universités américaines.
Dans la foulée, durant les années 1970, plusieurs grands réseaux décentralisés naissent aux États-Unis et en Europe.
En 1977, Vinton Cerf crée un nouveau protocole de communication, TCP/IP, qui permet de gérer les communications de manière beaucoup plus souple : il tolère les erreurs de transmission, supporte des changements de configuration du réseau en temps réel, etc.
À partir de 1983, le protocole TCP/IP s'impose progressivement au reste du monde, et va permettre d'unifier les différents réseaux publics existants qui se raccordent peu à peu à Arpanet.
Celui-ci prend alors le nom d'Internet.
Depuis 1998, Internet est placé sous la tutelle de l'ICANN, un organisme dont le siège est en Californie.
Au fil des années, Internet prenant de l'importance, le rattachement de l'ICANN à l'administration américaine a été vu d'un mauvais œil par de nombreux pays. En 2016, l'ICANN est enfin devenue indépendante.
Quelques principes de base
Chaque ordinateur (PC, smartphone, objet connecté, etc.) possède une adresse IP unique permettant de l'identifier sur le réseau.
Cette adresse est traditionnellement (IPv4) de la forme N.M.P.Q où N, M, P et Q sont des nombres entiers entre 0 et 255.
Exemple : 130.42.1.61
Cela donc offre 2564 ≈ 4 milliards de possibilités.
Avec la multiplication des objets connectés, ce nombre est devenu insuffisant.
Le nouveau protocole IPv6 offre 2128 adresses possibles, soit environ 3×1038 possibilités (c-à-d. 300 milliards de milliards de milliards de milliards d'adresses différentes).
La notation décimale pointée employée pour les adresses IPv4 (par exemple 172.31.128.1) est abandonnée au profit d’une écriture hexadécimale, où les 8 groupes de 2 octets (16 bits par groupe) sont séparés par un signe deux-points : 2001:0db8:0000:85a3:0000:0000:ac1f:8001 par exemple.Wikipédia
So we could assign an IPV6 address to EVERY ATOM ON THE SURFACE OF THE EARTH, and still have enough addresses left to do another 100+ earths. It isn't remotely likely that we'll run out of IPV6 addresses at any time in the future.Steve Leibson
Bref, problème résolu.
Comme les adresses IP sont difficilement mémorisables par des humains, on utilise des noms de domaine à la place, qui sont convertis ensuite en adresses IP (et vice-versa) par des serveurs DNS.
Il existe 13 « serveurs racines » (en réalité environ 1000 serveurs physiques dans 53 pays) qui dépendent d'une composante de l'ICANN, l'IANA, mais qui sont gérés par 12 organisations : 2 sont européennes (RIPE NCC et Autonomica, une division de Netnod), une japonaise (WIDE), les autres étant américaines.
Exemple : fr.wikipedia.org désigne le sous-sous-domaine fr du sous-domaine wikipedia du domaine org.

Internet possède de nombreuses applications : mail (via les protocoles smtp, pop et imap), transfert de fichier (via ftp ou sftp), synchronisation horaire (protocole ntp), diffusion multimédia (protocole rtp), etc.
Mais l'application la plus connue d'Internet est bien sûr le « Web ».
Le web, késako ?
Le World Wide Web a été inventé en 1990 par Tim Beners-Lee, qui travaillait alors au CERN à Genève.
Il cherchait alors un moyen simple de partager des informations avec ses collègues.
Le web consiste en un ensemble de documents accessibles à tout ordinateur relié au réseau (Internet en l'occurrence), et reliés entre eux par des liens hypertextes.
On accède aux pages web hébergées par un ordinateur du réseau en utilisant le protocole http (ou https pour chiffrer la communication).
L'ordinateur qui cherche à accéder à une page web s'appelle le client ; celui qui héberge la page web s'appelle le serveur : le serveur répond à la requête du client.
Pour accéder à une page web, l'ordinateur client utilise un navigateur (Firefox, Chrome, Edge, Safari...) dont le moteur de rendu (Gecko, Blink, Webkit, se chargera d'afficher le contenu.
Pour que différents navigateurs puissent consulter différentes pages web, il faut que les créateurs de pages et les concepteurs de navigateur se mettent d'accord sur un langage commun. Tim Berners-Lee crée dans ce but le HTML, un langage de balisage inspiré du GML d'IBM (1969).
Aujourd'hui, un consortium d'entreprises et d'institutions, le W3C, gère les spécifications du langage et œuvre pour assurer leur respect par les différents navigateurs.
| Principales versions de HTML | |
|---|---|
| HTML | 1991 |
| HTML 2.0 | 1995 |
| HTML 3.2 | 1997 |
| HTML 4.01 | 1999 |
| XHTML | 2000 |
| HTML 5 | 2014 |
| HTML 5.2 | 2017 |
On note qu'entre HTML4 et HTML5, 15 ans se sont écoulés.
La domination écrasante d'Internet Explorer, installé d'office avec Windows, bloque pendant de nombreuses années l'innovation sur le web. Il s'écoule notamment plus de 5 ans entre la sortie d'Internet Explorer 6 et celle d'IE7 fin 2006...
Les grands principes du HTML
Structure, contenu et mise en forme
À l'origine, le code HTML gérait à lui seul tout l'affichage de la page.
Rapidement, on s'aperçut que cela posait de nombreux problèmes, en particulier :
- code moins lisible et moins évolutif
- difficulté pour adapter le rendu au support (écran de smartphone ou écran de télé, navigateur braille, ...)
Les feuilles de styles (CSS) ont été inventées pour résoudre ce problème.
Le code HTML ne s'occupe désormais que de la structure du document. Toute la mise en forme s'effectue via une (ou plusieurs) feuilles de style, complètement séparées.
Cette séparation en deux langages aux finalités bien distinctes a permis au HTML et au CSS d'évoluer et de gagner énormément en fonctionnalité au fil des versions, tout en restant bien lisibles.
En bref : on structure un contenu (texte, images...) à l'aide du HTML. On le met ensuite en forme à l'aide du CSS.
On peut voir également les balises HTML comme des métadonnées, c'est-à-dire des informations supplémentaires concernant les données (c-à-d. le contenu) : on précise que tel morceau de texte est important, que tel autre est une citation, qu'une partie du contenu sert de menu de navigation, etc.
Le HTML sert ainsi de support au web sémantique, à travers des extensions comme RDF qui permettent aux robots parcourant le web d'extraire facilement des informations des pages web.
- le code source est plus lisible ;
- le code est plus évolutif (on peut faire évoluer le style et le contenu de manière indépendante) ;
- le partage des tâches est facilité (un développeur s'occupe du contenu, un autre du style) ;
- on peut adapter l'affichage au support (taille de l'écran...) ou à l'utilisateur (personne handicapée) ;
- il est plus facile de conserver une charte graphique homogène (une feuille de styles commune à toutes les pages) ;
- le chargement des pages est un peu plus rapide (pour les mêmes raisons).
HTML : un langage de balisage
Le code HTML consiste en des balises, délimitant le plus souvent des portions de texte.
Une balise ordinaire s'ouvre et se ferme autour d'un contenu (qui peut contenir lui-même d'autres balises...) :
<balise> ← balise ouvrante
contenu
</balise> ← balise fermante
Il existe également quelques balises auto-fermantes :
<balise /> ← pensez à la barre oblique à la fin
Cas particulier, on commente le code en utilisant la syntaxe suivante :
<!--
Ceci est un commentaire, et n'apparaîtra donc pas dans le document.
-->
Une balise peut posséder un ou plusieurs attributs, permettant de paramétrer son fonctionnement.
<balise attribut1="valeur" attribut2="autre valeur">
Voici un premier exemple de code HTML :
<h2 id="elephants">Les éléphants</h2>
<p>On distingue 3 espèces d'éléphants : deux vivent en Afrique ; la dernière vit en Asie.</p>
<img src="images/elephants.jpg" alt="photo d'éléphant"/>
Dans cet exemple, on observe trois balises :
- les balises h2 et /h2 délimitent un titre (de niveau 2) ; elle a un attribut nommé id.
- les balises p et /p délimitent un paragraphe.
-
la balise img/ sert à insérer une image. Elle a deux attributs (src et alt).
On remarque qu'elle est auto-fermante : en effet, elle sert à insérer un objet, et non à délimiter un contenu.
HTML et XHTML
Le langage HTML a inspiré la création de XML, un format permettant de construire des langages à balisages faciles à traiter par ordinateur.
Les langages respectant les spécifications XML ont une syntaxe simple et régulière, qui les rend à la fois simple à manipuler par ordinateur et facile à lire par un humain au besoin.
Par ailleurs, comme c'est le standard de documents le plus répandu, l'immense majorité des langages de programmation usuels possèdent des bibliothèques permettant de lire ou d'écrire très facilement du code XML.
HTML étant antérieur au XML, sa syntaxe est moins stricte. Cependant, on peut très bien écrire du code HTML respectant la syntaxe XML : on parle alors de XHTML.
Écrire du XHTML ne change rien au niveau affichage, mais permet d'avoir un code plus lisible.
Cela permet également d'utiliser les nombreuses bibliothèques XML disponibles pour modifier automatiquement le code par exemple.
- Les noms des balises et des attributs sont toujours écrits en minuscules.
- Toute balise ouverte doit être fermée.
Pour les balises auto-fermante, on n'oublie pas la barre oblique finale. Exemple: br/ - Les balises doivent être fermées dans le bon ordre.
Par exemple, pemtexte/em/p est correct, mais pas pemtexte/p/em. - Chaque attribut doit avoir une valeur, écrite entre guillemets (simples ou double).
Ainsi, on écrira <input type="checkbox" checked="true"/>
(et non <input type="checkbox" checked> qui est valide en HTML, mais pas en XML).
Nous écrirons systématiquement du code XHTML 5.
Au travail !
Environnement de travail
Nous travaillerons dans Mes Documents/M115/web/TD1/, commencez donc par créer les répertoires correspondants.
Lancez ensuite l'éditeur HTML Brackets, et ouvrez dans Brackets le dossier Mes Documents/M115/web/TD1/, pour créer un nouveau projet.
Créez ensuite un nouveau fichier (Ctrl+N) que vous enregistrerez immédiatement sous le nom td1.html.
Premier exemple
Voici un premier exemple de code HTML :
<!DOCTYPE html>
<html>
<body>
<h1>TD 1 - À la découverte de HTML</h1>
<p>Voici un
premier
paragraphe.</p>
<p>En voici un autre.</p>
</body>
</html>
Copiez ce code HTML dans le fichier que vous venez de créer.
Enregistrez (Ctrl+S), puis activez l'aperçu en direct dans Brackets à l'aide du bouton en forme de zigzag en haut à droite de l'éditeur ou du raccourci clavier Ctrl+Alt+P (ou encore depuis le menu Fichier).
Vous devriez voir votre page se charger dans Chrome.
Modifiez le contenu de la page, et vérifiez que l'affichage dans Chrome se met à jour en temps réel.
On remarque que le navigateur associe un style par défaut aux différentes balises.
Il ne faut pas accorder d'importance à ce style, puisque c'est la feuille de styles CSS qui définira les styles appliqués aux différentes balises.
Les styles par défaut ont souvent une raison historique : avant la création de CSS, les balises HTML servaient également à la mise en forme.
Les sauts de lignes dans le code source d'un fichier HTML n'apparaissent pas sur la page.
N'hésitez pas à sauter des lignes dans le code source pour le rendre plus lisible.
C'est les paragraphes (entre autres) qui permettront d'obtenir des sauts de ligne sur la page web.
Le CSS permettra de gérer l'espacement entre les paragraphes.
Dans le menu Fichier, choisissez Gestionnaire d'extensions. Installez l'extension Beautify.
Cette extension permet de formater automatiquement le code HTML pour qu'il reste lisible (Ctrl+Alt+B ou utilisez le bouton « baguette magique » en haut à droite de Brackets).
Encore plus simple : choisissez de formater automatiquement le code à chaque sauvegarde. Pour cela, allez dans le menu Modifier et sélectionnez Beautify on Save.
Validation et rendu
Tester la validité sur le site du W3C
Le W3C (consortium chargé de définir les normes du web) a créé un site web permettant de vérifier la validité d'une page HTML.
Allez sur le site internet du w3c et testez la validité de la page précédente.
Vous remarquez que le validateur affiche des erreurs et des avertissements, alors que le rendu de la page est correct dans le navigateur.
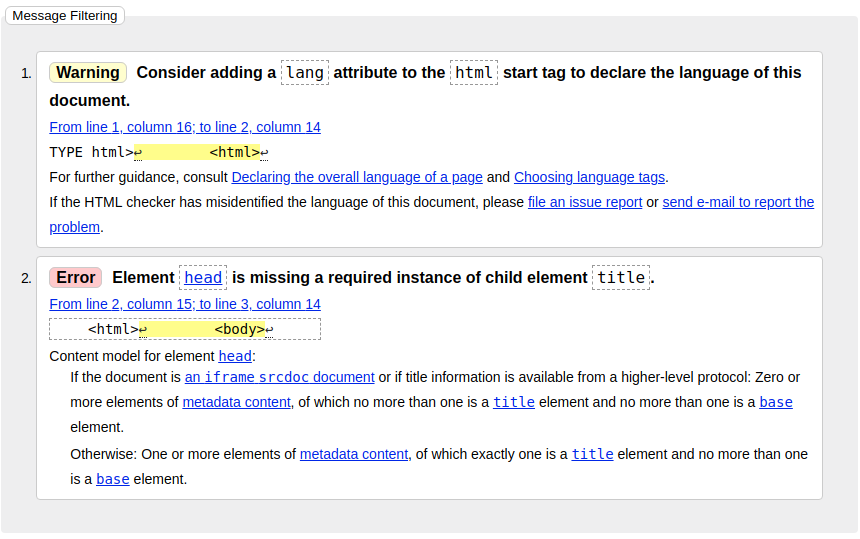
Le validateur du W3C vous indique où se situe le problème (ligne et colonne), et vous donne des explications détaillées... (yet only in english of course !)
Ici, le problème vient du fait qu'une page HTML doit avoir une entête, précisant un certain nombre d'informations relatives à la page (titre, langue, encodage, feuille de style...)
Nous y reviendrons.
Rappel : dans le menu Fichier, cliquez sur Gestionnaire d'extensions.
À chaque sauvegarde (Ctrl+S), votre fichier HTML sera analysé.
Le résultat de la validation s'affiche en bas à droite de la fenêtre.
- Fichier incorrect : cliquez sur le panneau "Attention" pour que les erreurs s'affichent.
- Fichier valide :

Validation vs rendu
La validation d'une page HTML est indispensable, même lorsque son rendu semble correct.
En effet, les navigateurs internet sont très tolérants, leur but étant de procurer à l'utilisateur une expérience de navigation la plus satisfaisante possible. Ainsi, si la page web ne contient pas trop d'erreurs, le navigateur arrive en général à les corriger.
Ce n'est cependant pas une raison pour écrire du code incorrect, d'autant que les erreurs, souvent faciles à corriger au départ, peuvent en s'accumulant finir par provoquer des bugs plus compliqués à résoudre.
À l'inverse, il se peut que votre code HTML soit correct, mais qu'un ou plusieurs navigateurs ne le rende pas correctement. En effet, comme le HTML et surtout le CSS évoluent très rapidement, certaines nouveautés ne sont pas (encore) implémentées dans tous les navigateurs - ou parfois mal implémentées.
Ceci sera particulièrement vrai pour le CSS. Le site Can I Use permet de savoir, pour chaque fonctionnalité HTML/CSS, quels sont les navigateurs qui l'implémentent, et à partir de quelle version. Il indique également les parts de marché de ces différents navigateurs pour chaque version. (C'est une information importante : si une vieille version d'un navigateur n'est presque plus utilisée, on peut économiser du temps de développement en arrêtant de la supporter.)
Le cœur du navigateur est son moteur de rendu. Les moteurs de rendus principaux sont :
- Gecko (navigateur Firefox)
- Webkit (navigateur Safari)
- Blink (navigateur Chrome) qui est dérivé de Webkit (on parle de fork)
- EdgeHTML (navigateur Edge) qui est dérivé de Trident (Internet Explorer)
Il existe un grand nombre de navigateurs exotiques, mais ils utilisent presque tous un de ces 4 moteurs de rendu, car le développement d'un moteur de rendu original serait un travail considérable.
À chaque fois que vous modifiez votre page web :
- Vérifiez le rendu dans votre navigateur habituel (Chrome ou Firefox de préférence)
- Vérifiez sa validité sur le site du W3C.
- Testez le rendu dans un autre navigateur (Chrome si vous utilisiez Firefox, et vice-versa)
À la fin, si tout fonctionne bien, vérifiez le rendu dans les autres navigateurs (Safari et Edge au minimum ; idéalement vérifiez aussi que le rendu n'est pas trop mauvais sous Internet Explorer).
Lorsque vous rendrez un site web, les fichiers HTML et CSS seront systématiquement testés sur le validateur W3C. Toute erreur de validation sur un travail rendu serait fortement pénalisée.
Pour ne pas perdre de point, ne rajoutez pas une fonctionnalité au dernier moment sans l'avoir validée !
Fichier par défaut
Lorsque votre site web est hébergé par un serveur, il est fortement recommandé de créer un fichier index.html à la racine de votre site web.
En effet, si quelqu'un tape l'adresse de votre site web sans spécifier de page web précise, c'est le fichier que votre serveur va chercher à afficher (il est possible cependant de paramétrer différemment le serveur).
Exemple : si l'utilisateur tape dans la barre de son navigateur http://www.monsite.com, le serveur affichera par défaut la page http://www.monsite.com/index.html, si elle existe.
En l'absence de ce fichier, le serveur renvoie en général la liste des fichiers du répertoire.
La page d'accueil de votre site web doit s'appeler index.html.
Créez dans votre dossier web un fichier nommé index.html, et écrivez dedans le code suivant :
<h1>HTML et CSS</h1>
<p>Voici la page d'accueil du site web regroupant mes différents TD.</p>
L'entête d'un document HTML
Présentation générale
En plus du contenu à afficher sur la page, un document HTML doit comporter un certain nombre d'informations utiles au navigateur et aux moteurs de recherche.
Ces informations ne seront pas affichées sur la page web, mais aideront le navigateur à effectuer un rendu correct de celle-ci. Elles servent aussi aux moteurs de recherche pour l'indexation de la page.
Tout d'abord, on doit préciser qu'il s'agit d'un document HTML5.
À cet effet, le document doit systématiquement commencer par la balise spéciale !DOCTYPE html.
Ensuite, le reste du document est contenu entre les balises html et /html. On en profitera pour préciser la langue du document :
<!DOCTYPE html> ← c'est un document HTML5
<html lang='fr'> ← il est en français
<head>
... ← l'entête
</head>
<body>
... ← le corps du document
</body>
</html>
Intéressons nous maintenant à l'entête, qui est délimitée par les balises head et /head.
L'entête doit au minimum préciser :
- l'encodage, bien que celui-ci soit systématiquement en utf-8 sur les sites web modernes
- le titre du document, qui sera affiché en haut de la fenêtre du navigateur (et non dans la page elle-même !)
- l'emplacement d'une ou plusieurs feuilles de styles
- l'emplacement d'éventuels fichiers Javascript
D'autres information peuvent y figurer, notamment un résumé du contenu de la page.
Voici un exemple complet d'entête.
<head>
<!-- Partie obligatoire -->
<meta charset = 'utf-8'/> ← encodage (toujours en premier !)
<title>Le lac de Paladru</title> ← titre
<!-- Partie facultative -->
<meta name = 'description'
content = 'Histoire du lac de Paladru, du néolithique à nos jours.'/> ← résumé
<meta name = 'author' content = 'A. Jaoui'/> ← auteur
<link rel = 'stylesheet' href = '../styles/dark.css'/> ← feuille de styles CSS
<script src = '../js/menu.js'/></script> ← fichier Javascript
</head>
En s'inspirant de l'exemple précédent, modifiez les fichiers td1.html et index.html afin qu'ils passent le test de validation du W3C.
L'entête sert également au référencement et à l'affichage des résultats par les moteurs de recherche :

Quelques mots sur l'encodage
L'encodage est la manière dont on stocke un texte sur un ordinateur.
Pour être stocké dans la mémoire de l'ordinateur, chaque caractère doit être représenté par un nombre binaire.
Historiquement, les textes étaient encodés en ASCII (American Standard Code for Information Interchange), standard développé dans les années 60. Chaque caractère était stocké sur 7 bits, ce qui permettait uniquement d'afficher 27=128 caractères.

L'ASCII permettait d'écrire de l'anglais et d'afficher des calculs simples, mais avec le développement d'Internet dans le monde, de nombreuses extensions de l'ASCII ont été créées, permettant d'afficher différents alphabets.
Ces extensions, généralement codées sur 8 bits (28=256 caractères) étaient incompatibles entre elles, provoquant fréquemment des problèmes d'affichage, dans les mails ou sur les sites web notamment. Par ailleurs, certaines langues (comme le chinois) nécessitaient plus de 256 caractères ; de même l'affichage de textes scientifiques nécessitait beaucoup de symboles différents.
C'est pour ces raisons que fut créé en 1991 une table de caractères universelle, nommée Unicode. La version 11 (juin 2018) énumère 137 374 caractères différents !
Il existe plusieurs implémentations d'Unicode (UTF-16, UTF-32), mais la plus connue est UTF-8. C'est un encodage à longueur variable, c'est-à-dire que tous les caractères ne sont pas encodés sur le même nombre de bits. Ceci permet à UTF-8 d'offrir une implémentation complète d'Unicode tout en consommant peu de mémoire lorsqu'on n'utilise que les caractères courants (un texte ASCII convertit en UTF-8 ne consomme que 14% de mémoire supplémentaire, contre +129% en UTF-16 et +357% en UTF-32).
Bref, de nos jours, l'UTF-8 est devenu le standard pour l'encodage de documents (seul Microsoft, par inertie, persiste encore à privilégier l'UTF-16).

Si vous parlez bien anglais, cette page explique plus en détail l'histoire d'Unicode et les avantages de l'UTF-8.
- Précisez la langue du document : html lang='fr'.
- Toutes vos pages web doivent être encodées en UTF-8 : meta charset='utf-8'.
- Elles doivent avoir un titre : title.../title.
Ce titre n'apparaît pas sur la page, mais sert au navigateur et aux moteurs de recherche.
Si jamais vous utilisez chez vous un autre éditeur de code que Brackets, assurez vous qu'il enregistre bien vos fichiers en UTF-8 !
Le contenu à proprement parler du document se situera entre les balises body et /body : c'est ce qu'on appelle le corps du document.
Voici le contenu minimal d'une page web vierge valide :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8" />
<title>Titre de mon document</title>
</head>
<body>
</body>
</html>
Enregistrer ce document sous le nom page_vierge.html ; celui-ci vous servira de template (c-à-d. de modèle) à chaque fois que vous créerez un nouveau document.
Le corps du document
Voyons maintenant les balises les plus courantes permettant de structurer le corps du document.
Les balises structurelles
La première étape consiste à réfléchir à l'architecture de votre page web. Comment sera organisé son contenu ?
Une page web typique possède des titres, des sous-titres (le contenu sera subdivisé en sections), un menu de navigation...
Les titres
Les balises h1, h2... h6 permettent de définir des titres de niveau 1, niveau 2,... niveau 6.
Voici un exemple de code HTML :
<main>
<h1>Les éléphants</h1> ← Titre de la page (unique donc !)
<section>
<h2>Les éléphants d'Afrique</h2> ← Un sous-titre
<p>Il existe deux espèces d'éléphants d'Afrique.</p>
<section>
<h3>L'éléphant d'Afrique de savane</h3> ← Un sous-sous-titre
<p>C'est le plus gros mammifère terrestre.</p>
<p>Même les enfants le connaissent.</p>
</section>
<section>
<h3>L'éléphant d'Afrique de forêt</h3> ← Un 2e sous-sous-titre
<p>Plus petit que son cousin des savanes, il est en danger critique d'extinction.</p>
</section>
</section>
<section>
<h2>Les éléphants d'Asie</h2> ← Un autre sous-titre
<p>L'éléphant d'Asie est plus petit et plus calme que celui d'Afrique.</p>
</section>
</main>
Les moteurs de recherche utilisent également les titres pour savoir de quoi parlent principalement une page web.
- title sert au navigateur (titre de la fenêtre, nom de l'onglet) et pour afficher les résultats du moteur de recherche.
- h1 sert à afficher le titre principal dans la page.
Les principales parties du page web
Voici une des architectures les plus courantes pour le corps de texte d'un document HTML :

Les balises utilisées ici sont :
-
header qui indique l'entête visible du document (à ne pas confondre avec head !).
C'est là qu'on place généralement le titre principal (balise h1) de la page.
- nav correspond à un menu ou une barre de navigation.
-
main indique la partie principale de la page.
Elle sera subdivisée en sections (balise section) (éventuellement imbriquées) comportant généralement des titres secondaires
- aside est utilisé pour des annexes (par exemple, une liste de liens externes sur un blog).
-
footer correspond au pied de page.
On peut s'en servir pour afficher des informations légales sur le site par exemple.
Ces balises précisent la structure de la page.
Elles ne disent pas comment la page sera affichée, ce qui est le rôle du CSS (à la rigueur, vous pouvez afficher votre entête en bas de la page !)
En particulier, il est fréquent de changer la mise en page lorsque l'on change de support (smartphone par exemple) - on parle de site web réactif. Pour autant, la structure, elle, n'est pas modifiée.
Structurez votre page td1.html. Celle-ci devra comporter :
- Une entête (header) contenant le titre principale (balise h1).
- Une partie main contenant notamment les réponses aux questions qui vous seront posées dans la suite du TD.
- Un pied de page (footer) qui contiendra votre nom ainsi que la date de création de la page.
D'autres balises structurelles
-
La balise article sert à créer des articles (si !) c'est-à-dire des contenus indépendants entre eux. On utilisera la balise article pour les posts d'un blog par exemple.
Il ne faut pas confondre un article avec une section, qui est une partie seulement d'un unique contenu (les différentes parties d'un texte par exemple).
-
La balise menu sert à créer des menus interactifs, permettant d'effectuer des actions sur la page.
Elle est donc essentiellement utile pour créer des applications Web.
Elle ne doit pas être confondue avec la balise nav, qui sert à créer des menus de navigation.
Les balises de texte
Une fois notre page structurée, il est temps de nous intéresser au contenu.
Les balises suivantes servent à structurer non plus la page, mais un morceau de texte.
Attention, ce sont souvent d'anciennes balises qui existaient déjà en HTML3 ou 4, mais dont l'usage a changé en HTML5. Lorsque vous cherchez de la documentation ou des exemples sur Internet, faites attention à la date... s'ils sont antérieurs à 2014 (publication de HTML5), ils risquent fort de ne pas être à jour !
Voici les balises les plus courantes :
-
p indique un paragraphe
<p>L'idée du Web est née d'un mémo rédigé par Tim Berners-Lee en mars 1989, intitulé : "gestion de l'information: une proposition".</p> <p>Il expliquait comment un système basé sur les liens hypertextes et des ordinateurs connectés entre-eux pouvait aider les chercheurs du Cern à mieux partager leurs informations, et à mieux y accéder.</p> -
strong indique quelque chose d'important
<strong>Veuillez valider les conditions générales de vente.</strong> -
em (« emphase ») permet d'insister sur quelque chose
Le format AAC n'est <em>pas</em> supporté. - La balise b servait en HTML3 à mettre en gras. Elle sert désormais à mettre en valeur certains mots (par exemple, des mots-clés, des noms de produits, etc.) sans qu'on cherche spécialement à insister dessus.
- La balise i servait en HTML3 à mettre en italique. Elle sert désormais à indiquer qu'un mot doit avoir une typographie différente (par exemple un mot en langue étrangère dans un texte).
-
La balise sup sert à mettre en exposant, et la balise sub sert à mettre en indice.
On pose u<sub>n</sub>=2<sup>n</sup>. - code permet de citer un extrait de code informatique.
<code>var a = 2;</code> - q introduit une courte citation (un morceau de phrase)
<q>être ou ne pas être</q>, disait <cite>Shakespeare</cite>, <q>voilà la question</q>. - blockquote est utilisé pour une citation longue (un ou plusieurs paragraphes).
<blockquote> <p>Science is what we understand well enough to explain to a computer. Art is everything else we do.</p> <p><cite>Donald Knuth</cite></p> </blockquote>
Expliquez ce qu'est une URL et une URI, en étayant vos explications par des extraits de Wikipédia (balises blockquote ou q et balise cite).
Utilisez la balise b pour mettre en valeur les mots-clés URL et URI et la balise em pour insister sur des points qui vous semblent importants.
Insertion d'une image
La balise img/ permet d'insérer une image :
<img src='mondossier/monimage.gif' width='50' height='60' alt="exemple d'image"/>
Les formats d'image acceptés par tous les navigateurs récents sont PNG, JPG, GIF et SVG.
D'autres formats ont un support partiel : par exemple APNG est désormais supporté par tous les navigateurs sauf Edge.
Remarque : il est possible de rajouter le support d'autres formats (comme FLIF, qui est un format d'image moderne très performant) en intégrant des bibliothèques Javascript à sa page web.
Vous pouvez visualiser sur cette page les différences de rendu de plusieurs formats d'image avec perte.
Dans le fichier td1.html, répondre aux questions suivantes :
- Qu'est-ce qu'un format d'image matriciel ? Vectoriel ? Avec perte/sans perte ?
- Quelle sont les différences entre les formats PNG, GIF, JPG et SVG ?
- Pour quel usage est conseillé chaque format ?
- De nouveaux formats d'images ont vu le jour récemment : JPEG2000, WebP, APNG, JPEG-XR, BPG, FLIF... Quels sont leurs points forts/points faibles ?
L'attribut src
L'attribut src indique l'adresse de l'image dans l'arborescence du site.
Soit l'arborescence suivante d'un site situé sur un serveur « monsite.com » dans un dossier « www/ » :
+- www +- img | +- monimage.jpg +- dossier +- page.html ← page contenant la balise img/
Cette adresse peut-être :
-
Relative à notre fichier page.html.
Par exemple, ../img/monimage.jpg. Le chemin s'écrit comme sous UNIX - en particulier les .. indiquent qu'en partant de notre fichier HTML, il faut commencer par remonter d'un niveau dans l'arborescence pour trouver img/monimage.jpg :
- Absolue
- soit l'adresse locale sur le serveur (exemple : /img/monimage.png)
- soit l'URL c-à-d. l'adresse internet (exemple : http://monsite.com/img/monimage.png).
Lorsqu'on a le choix (images hébergées localement), il faut privilégier les adresses relatives, qui permettent de changer facilement l'emplacement du site, sans avoir à réécrire toutes les adresses.
Par ailleurs, il est conseillé de regrouper toutes vos images dans un même dossier (img/ ou images/ par exemple) pour plus de clarté.
Insérez cette image dans td1.html en 500px×400px (n'oubliez pas l'attribut alt !).
{kind=link}
L'attribut alt
L'attribut alt sert à indiquer un texte de remplacement, au cas où l'image ne soit pas affichée.
À quoi cela sert-il ?
- Il se peut que lien vers l'image soit cassé.
- Certains navigateurs n'affichent pas les images. En particulier, les navigateurs à synthèse vocale pour les personnes aveugles peuvent ainsi « lire l'image ».
- Cela facilite le référencement de la page par les moteurs de recherche.
Pour toutes ces raisons, vous devrez toujours donner un attribut alt à toutes vos images.
Exemple :
<img src='img/campus.png' alt="Vue d'ensemble du campus."/>
Dimensions de l'image
Les dimensions de l'image sont données en pixels (en HTML5, on ne précise plus l'unité).
Il est possible de spécifier seulement la hauteur ou seulement la largeur. Dans ce cas, le ratio hauteur/largeur est automatiquement conservé (c-à-d. que l'image n'est pas déformée).
Par défaut, si aucune dimension n'est donnée, l'image est affichée en taille réelle.
Il est cependant conseillé de toujours préciser les dimensions :
<img src='img/campus.png' width="160" height="90" "alt="Vue d'ensemble du campus."/>
Cela permet :
- de ne pas casser la mise en page si jamais le lien vers l'image est cassé ;
- d'accélérer le rendu de la page (le navigateur peut commencer à afficher la page avec son rendu définitif sans avoir encore téléchargé toutes les images).
Remarque : on peut aussi donner les dimensions avec CSS, mais dans ce cas le rendu sera moins rapide. Par contre, CSS permet de donner les dimensions de l'image en pourcentage (ce qui n'est pas autorisé en HTML5).
Créer des liens
Principe
Les liens hypertextes, appelés aussi ancres ou hyperliens, sont l'idée principale à l'origine des documents HTML ; HTML étant l'acronyme de HyperText Markup Language.
On crée un lien à l'aide de la balise a (a comme ancre).
L'attribut href (Hypertext Reference) indique l'URL de la cible (c-à-d. son adresse internet).
Cette dernière peut être une autre page internet, mais également un fichier à télécharger, une adresse FTP, une adresse mail...
Exemple :
<a href="page2.html">Cliquez ici</a>
Comme pour les images, l'adresse peut être relative...
<a href="../index.html">Revenir à l'accueil</a>
...ou absolue :
Cette <a href="https://fr.wikipedia.org/wiki/B%C3%A9po">page</a> est très intéressante.
On peut remplacer le texte cliquable par une image :
<a href="http://fr.wikipedia.org"><img src='img/wikipedia.png' alt='Wikipédia'/></a>
Créez une page a_propos.html dans votre dossier web donnant quelques informations succinctes sur vous :
- Une photo
- Nom et prénom
Créez un lien vers cette page depuis index.html et td1.html.
L'attribut target
L'attribut target sert à spécifier la cible du lien, c'est-à-dire où est-ce que doit s'ouvrir la nouvelle page lorsqu'on clique sur le lien.
Les valeurs les plus courantes sont :
- "_self" : affiche la page dans l'onglet actuel (comportement par défaut)
<a href="utilisateur.html" target='_self'>manuel d'utilisation</a> - "_blank" : affiche la page dans un nouvel onglet
<a href="installateur.html" target='_blank'>manuel avancé pour l'installateur</a> - on peut aussi spécifier un nom personnalisé ; tous les liens qui ont pour cible ce même nom s'ouvriront dans un même onglet.
<a href="utilisateur.html" target='doc'>manuel d'utilisation</a>
<a href="installateur.html" target='doc'>manuel avancé pour l'installateur</a>
Dans l'exemple précédent, les deux liens ont une même cible (nommée « doc »). Si l'on clique sur le premier lien, la page utilisateur.html se chargera dans un nouvel onglet. Mais si l'on clique ensuite sur le 2e lien, la page installateur.html s'affichera à la place de utilisateur.html, dans le même onglet, puisque ces deux liens ont la même cible.
Répondre aux questions suivantes dans le fichier td1.html :
- En général, vaut-il mieux utiliser "_blank" ou "_self" comme valeur de target (et pourquoi) ?
- Y a-t-il des exceptions ? Lesquelles et pourquoi ?
Courrier électronique
Il est également possible de mettre en lien une adresse mail.
Ceci est fréquemment utilisé dans la section « Contact » d'un site web.
<a href="mailto:donald.knuth@unice.fr">Contacter M. Knuth</a>
Pour que cela fonctionne, il faut cependant que le navigateur soit configuré pour autoriser et prendre en charge l'envoi de courriels.
Attention, c'est également le meilleur moyen de livrer votre adresse mail aux robots de SPAM.
Pour contourner ce problème, on peut essayer de ruser, par exemple :
Il est également possible de préciser le sujet et le corps de texte du courriel :
<a href="mailto:bugs.bunny@cartoon.univ-cotedazur.fr?subject=Hello Bunny&body=What's up doc ;)">Contacter Bugs Bunny !</a>
-
Écrire l'adresse en toute lettres. Par exemple, prenom point nom at unice point fr au lieu de prenom.nom@unice.fr.
Inconvénient : on perd le lien. Par ailleurs, certains robots spammeurs peuvent avoir des algorithmes de détection relativement sophistiqués pour traduire ce genre d'écriture.
-
Utiliser un script JavaScript pour encoder l'adresse mail.
Inconvénient : le robot peut être suffisamment sophistiqué pour interpréter le code Javascript.
-
Insérer une image compréhensible seulement par un humain.
Inconvénient : cela diminue l'accessibilité du site aux personnes malvoyantes.
On trouve sur SuperUser un comparatif intéressant (quoiqu'un peu daté) de différentes méthodes de lutte contre la collecte automatique d'adresses mail et leur efficacité relative.
- Complétez la page a_propos.html avec votre adresse courrielle d'UCA.
- Si vous êtes un peu en avance sur les autres, cherchez également sur Internet un script Javascript pour encoder votre adresse mail, et faites apparaître votre adresse mail des deux manières sur votre page web. Vérifiez que les deux fonctionnent bien.
Les listes
Il existe deux types de listes : ordonnées et non ordonnées.
Là encore, ce n'est pas d'abord une question d'affichage : on peut afficher une liste avec ou sans numéros, qu'elle soit ou non ordonnée. Il s'agit plutôt de savoir si fondamentalement, l'ordre d'énumération est important.
- ol crée une liste ordonnée
- ul crée une liste non ordonnée
- li indique un élément d'une liste (ordonnée ou non)
Les listes peuvent être imbriquées.
Voici un exemple :
<ol>
<li>Retirer de l'argent</li>
<li>Faire les courses
<ul>
<li>pain</li>
<li>riz</li>
<li>œufs x 6</li>
<li>haricots</li>
</ul>
</li>
<li>Faire le plein d'escence</li>
</ol>
Ce qui donne :
- Retirer de l'argent
- Faire les courses
- pain
- riz
- œufs x 6
- haricots
- Faire le plein d'escence
- Complétez la page a_propos.html avec une liste de vos centres d'intérêts.
- Dans la page index.html, créez un titre de niveau 2 nommé sommaire, puis une liste de liens vers td1.html et td2.html (ce dernier fichier étant à créer).
Structurez votre fichier td1.html avec des listes.
En particulier, pour les réponses aux questions sur les formats d'images, ainsi que pour celles sur les cibles de liens, utilisez des listes ordonnées (ol).
Vérifiez au passage que votre page td1.html est bien structurée (titre h1, sous-titres h2...).
Plus de balises
Les balises "neutres"
Si vous regardez le code source d'un site web (Ctrl+U dans votre navigateur préféré), vous remarquerez des nombreuses balises div et span.
Ces balises n'ont aucune signification sémantique ou structurelle (elle n'apportent pas d'informations sur le contenu de la page), mais servent juste de support pour la mise en page (ou pour Javascript).
Elles ne nous intéressent donc pas pour l'instant.
Nous en reparlerons par contre lorsque nous aborderons le CSS.
The Never Ending Tour...
Il existe au total un peu plus d'une centaine de balises HTML5.
En voici une liste complète (les balises grisées ne sont plus utilisées en HTML5).
Parmi les balises importantes non abordées dans ce TD, notons les balises de multimédia, de formulaires, ainsi que celles permettant de faire des tableaux.
Elles seront l'objet de TD ultérieurs.
Les entités HTML
Certains caractères ont une signification spéciale en HTML. Par exemple, le caractère < sert à signaler le début d'une balise.
Pour afficher ces caractères spéciaux, on utilise alors des séquences spéciales de caractères appelées HTML entities (entités HTML). Ces séquences de caractères sont toutes construite de la même manière : &nom;.
Historiquement, les entités HTML servaient également pour afficher un grand nombre de caractères non représentables en ASCII (par exemple é pour le « é », mais depuis l'utilisation d'UTF-8, cet usage n'a plus beaucoup d'utilité.
Les entités HTML vraiment utiles de nos jours sont :
| Caractère spécial | Entité HTML |
|---|---|
| > | > |
| < | < |
| & | & |
| " | " |
| espace insécable | |
Un espace insécable sert à indiquer que le navigateur ne doit pas effectuer de retour à la ligne à cet endroit. On l'utilise par exemple avant certains signes de ponctuation (en français, devant le point d'exclamation ou d'interrogation, les deux-points ou le point-virgule notamment).
Il est préférable d'utiliser un espace insécable ( ) avant le point
d'exclamation, pour éviter que ce dernier se retrouve tout seul à la ligne
!
La liste complète des entités HTML est disponible sur cette page.
- Utilisez une entité HTML pour encoder le arobase @ de votre courriel sur la page a_propos.html (ceci permet de diminuer un peu le risque de récupération automatique de l'adresse mail par les robots spammeurs).
- Rajoutez des espaces insécables devant les signes de ponctuation « : ! ? ; ». (Ctrl+H est votre ami !)